A pure HTML AJAX based viewer is a zero footprint viewer capable to render documents and images in the browser and in the mobile devices. Doesn’t require any client-side installation, hence named it as “Zero Footprint” viewer. Highly customizable viewer that can be freely distributed along with documents in SharePoint or on the local machine. Among many advanced features, the viewer includes support for text search and highlighting, printing, export document to other files, redaction, annotations, etc. Viewer has a sleek and easy to use interface, therefore can be easily customized as per your needs. Allows viewing and editing document and image files and also supports annotations tools including redactions, text boxes, line, rectangle, circle, arrows, etc. Support different file formats including MS Office formats (doc, docx, xls, xlsx, ppt, pptx), PDF, TIFF, JPEG, BMP, etc.
Zero Footprint Solution
Using AJAX technology, viewer provides zero footprint solution to ensure data and corporate files are safe and secured. No trace of the opened files or related data is saved on the browser or workstation storage or on any mobile device. Capable to render documents and images in the browser and doesn’t require any client-side installation, hence named it as “Zero Footprint” viewer.

File Formats
Support viewing vast number of file formats - documents and images. Listed below are the most common file formats that are supported in eViewer - AJAX:
- Microsoft Word Document
- Microsoft Excel Spreadsheet
- PowerPoint Presentation
- PDF (Adobe Portable Document)
- TIFF (Tagged Image File)
- JPG(Joint Photographic Experts Group JPEG)
- MO:DCA (Mixed Object: Document Content Architecture)
- See all available formats supported
Annotate Files
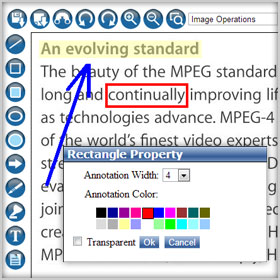
Includes annotation tools that allow easy review, collaboration, annotation and markup capabilities right in the viewer. Within a single user interface, you can freely write your own comments to the document and can share with others, reducing decision-making time, and increase collaboration for your users. Provides facility to add comments via sticky notes, apply digital stamps and much more thus making viewer an ideal solution for business work flow. Allows you to save, copy, paste and print annotation and contents. View, markup and annotate all at same time, all in one place. Add text, line, rectangle, circle, arrows, etc. to TIFF, PDF, JPG, and many more file formats.
Integration with ECMs
Enables you to search for and access your valuable document from any ECM. One can easily navigate documents collections as well as run searches to locate, view, and manage document. The following is the list of ECMs that we support:

Page On Demand Technology
Eliminate the need to download entire documents – access only those pages requested by the user for greatly enhanced high-speed viewing.

Compatibility with Browser
Pure HTML JavaScript based application compatible with any JavaScript enabled browser including mobile devices such as iPads, IOS devices Blackberry phones, Android etc.

eViewer - AJAX is loaded with rich features that make one of the most powerful viewers currently available. The following are some of the key features of the viewer that make it outstanding:
Viewing Tools
Provides functionalities such as Rotate, Zoom (In and Out), Fit to Presets, Navigate Pages / Documents, Thumbnails, Watermarks, Invert Colors of the page, Access via document thumbnail, etc
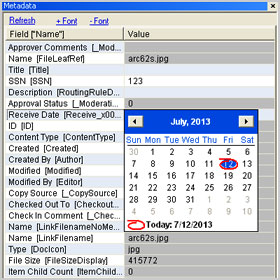
View & Edit Metadata Information
Presents metadata information in a structured way. Demonstrates how to view, edit, and save metadata information of JPEG, TIFF, MS Office formats, PDF files, etc. The metadata information of any file can be viewed or edited as per the need.
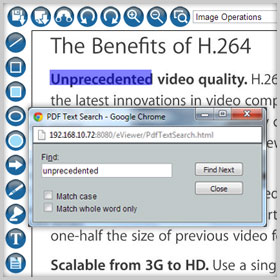
Searching Text
Allows you to quickly and easily search for a piece of information in any type of file through basic and advance search options. The search is easy, fast and convenient. The searched texts are then highlighted allowing user to navigate the searched information within the file. The text can be search either in the individual page or in the whole document.
Exclusive Features
Viewer is loaded with rich features that make it complete and outstanding. Some of the features are listed below
- Compatible with mobile devices
- Supports zero footprint solution
- Provides wide range of annotation tools such as line, arrow, rectangle, circles, etc.
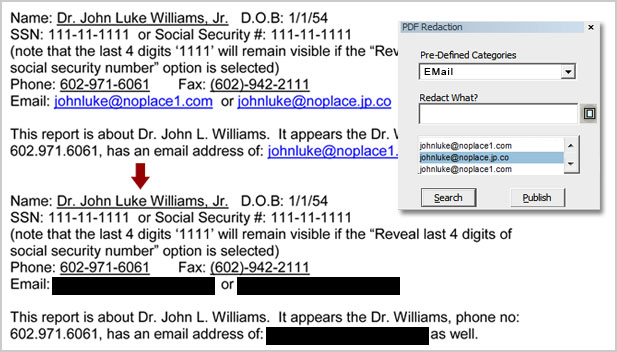
- Supports PDF redaction and hides sensitive and confidential information of a document
- View multiple documents in the viewer simultaneously
- Various image operations on any image
- Fit to presets – fit to window, fit to height, fit to width
- View document in thumbnail window
- Page and document navigation
Drag and Drop Pages
The most common way to copy the content of any page is to copy and then paste it in another page. New functionality has been in the viewer that supports drag and drop of pages from thumbnails. With this, one can easily drag page and drop it after or before any other page in the document.
View Multiple Documents
Easily view multiple documents simultaneously in one single browser window or tab. The multiple documents can be browsed easily from thumbnails and also from working set tree structure. The tree structured display the lists of document and their respective page which helps in easily isolating between the document being viewed.
In this section we have provided technical information of eViewer - AJAX. If you are unfamiliar with some of the topics listed, we strongly suggest you read up on each subject.
If you require further assistance with topics, please feel free to contact us.
 Formats
Formats Below are the lists of formats that we support for eViewer - AJAX
-
IBM proprietary file formats
- MO:DCA (Mixed Object: Document Content Architecture)
- IOCA (Image Object Content Architecture)
- PTK (PTOCA)
-
Office file formats
- DOC (Microsoft Word Document)
- DOCX (Microsoft Word Document 2007 & above)
- XLS (Microsoft Excel Spreadsheet)
- XLSX (Microsoft Excel Spreadsheet 2007 & above)
- PPT (PowerPoint Presentation)
- PPTX (PowerPoint Presentation 2007 & above)
- VSD (Microsoft Visio)
-
Documents
- PDF (Adobe Portable Document)
- RTF (Rich Text)
- TXT (ASCII Text)
-
CAD File Format
- DWG (AutoDesk Drawing)
Supported version R 12 or higher - DWF (AutoDesk Vector)
- DXF( Drawing Interchange)
-
Image file formats:
- ABIC
- BMP (Windows and OS/2 Bitmap Formats)
- CAL (CALS Raster)
- DCX (Paint Brush)
- DCM (DICOM)
- EMF (Windows Metafile)
- GIF(CompuServe GIF)
- JBG (JBIG)
- JB2 (JBIG2)
- JPG(Joint Photographic Experts Group (JPEG))
- JPEG-XR (Windows Media Photo / HD Photo (HDP))
- JPEG-LS (JPEG Lossless)
- J2K (JPEG 2000)
- JP2 (JPEG 2000 Compressed)
- JPM (JPEG 2000 Part 6)
- JPX (JPEG 2000 Part 2)
- PNG (Portable Network Graphics)
- PNM (Portable Bitmap Utilities)
- PPM (Portable Bitmap Utilities)
- PBM (Portable Bitmap Utilities)
- PCX (Paint Brush)
- RAS (SUN Raster)
- TIFF (Tagged Image File)
- WBMP (Wireless Bitmap)
- WMF (Windows Metafile)
- XPM (XPicMap)
Conversion Format Facilitate users to convert documents and images into more universal file formats for ease of use and portability. All the documents, images and CAD formats supported by the viewer mentioned above (in Formats group) can be converted into the following listed file formats
- JPEG
- IOCA
- MO:DCA
- TIFF
- GIF
- BMP
Below are the compression type formats that we support for encoding while conversion:
- RLE
- G3 Fax
- G4 Fax
- LZW
- JPEG
- Flate
- IBM MMR
Annotation | Annotation Tools |
|
Technical Specs eViewer is a client server application. The client being a javascript and Ajax based web app that runs on all browsers (IE6 or higher, Chrome, Firefox, Safari etc...) and server code in Java that run virtually on any Java supported application servers (such as IBM WebSphere, Oracle WebLogic, Apache Webserver, Apache Tomcat, Oracle GlassFish etc...). Java server supports deployment on RHLor Windows environment. Java server module also contains plugins connectors to connect virtually on any ECM (such as IBM CM8.xx, FileNetP8 4.5 or higher, Microsoft SharePoint 2007 - 2013, EMC Documentum etc...)
This product works on On-Demand technology. Documents are retrieved, cached on the server and JPEG streams sent to the viewer for rendering single or multiple pages on request.
Listed below are the functions performed by the viewer on the client browser without sending calls to the controller:
- Annotation Drawing
- Thumbnails
- Re-Order Pages using Drag And Drop
- Invert
- Flip Horizontal
- Flip Vertical
- Brightness & Contrast
- Grey Scale
- Enhance
Listed below are the viewer functions that send call back to the controller for processing On-Demand:
- Loading document (for retrieving JPEG stream, annotation and other supporting XML stream).
- Zoom In
- Zoom Out
- Page Navigation
- Fit To Width
- Fit To Height
- Fit To Window
- Rotate Clockwise
- Rotate Counter Clockwise
- Bookmarking
- Save Document, Annotations & Comments
- Exporting document to PDF with reordered pages, page rotation & redaction.
- Printing document
- Quick or Advance Text Search (to display search results for the whole document)
- Unloading document (Intimating the controller to drop the document from server)
- Annotations drawn on documents are saved as a separate XML index file, which is saved back to file system or ECM linked with the document, so as the same can be reloaded and annotations overlaid on the pages on document reload.
- Every annotation objects have a set of properties associated with them (such as ForeColor, Transparent, Font, Text, Width etc...), the default annotation property setting can be set using preference XML input.
- Annotations can also be made permanent on the image by annotation burn function. Once the annotations are burned they become part of the document. The document can be exported out as PDF or TIFF with annotations burned.
- Annotations can also be exported out to PDF as PDF annotation objects which can later be edited in PDF editor application.
- Viewer provides below listed set of annotation tools: Line, Rectangle, Ellipse, Highlight, Text Stamp, Image Stamp, Text, Sticky Note
- Viewer provides below listed set of Measurement Tools: Rectangle, Circle
Zooming
MST Viewer provides zoom in/out, custom zoom or rubber band zoom tools. Viewer zooms image or document preserving the quality of text and images event at higher or lower zoom values. It applies image filters such as Bilinear or Bi-Cubic Interpolation for images and zoom the text objects by modifying the corresponding font information to keep the text quality intact.
Rotate pages of a document or image and save them back without modifying their original properties (such as text searchable PDF etc...).
Automatically crops the unwanted white or black background from the image
Automatically straightens the scanned images
Applied during display to remove noise and display enhanced quality output for bi-level fax images. and much more...
Viewer retrieves the metadata associated with the document from the ECM and provides editing of the information based on the type of metadata field. Such as for a Date & Time field type a date and time picker is displayed and for a multiple choice field a multiple choice drop down is displayed. Below types of field type editing is supported: Date & Time, Single Line Text, Multiple Line Text, Single Choice, Multiple Choice, Number, Currency
Allow integration with SharePoint 2007 onwards. User can directly launch document from their document libraries into MST Viewer and save them back to SharePoint document library.
Allow integration with IBM CM8 Windows Client. Replace the default windows client viewer with MST Viewer to get a whole new set of features (such as enhance image quality for PDF documents, new set of annotation, image tools, page re-ordering, redaction capabilities etc...) on top of all the existing features present in the default IBM Windows Client viewer.
Allow integration with IBM FileNet P8 Workplace or WorkplaceXT. User can view single or multiple documents in the viewer from workplace or workplaceXT. Supports viewing of existing P8 annotation made using the default P87 viewer. Save the annotation back to the same P8 annotation format. Hence,annotations made by default FiletNet P8 viewer can be viewed by MST Viewer and vice-versa. Also provide integration with eForms and searching of documents from CE.
Provide plugins for IBM Content Navigator, to setup selected MIME types to be viewed with MST Viewer from CM8 or FileNet P8 repositories. Can be configured with SSO installation of Content Navigator.
Provide Mask annotation for manually redacting an area of document or image. MST Viewer provides programmatic access to its functions using activeX API's which can be used to drive the viewer functions programmatically from virtually any other application windows application.
Developer Reference
Upload Document  uploadDocument (viewerURL, documentUrl)
uploadDocument (viewerURL, documentUrl)
Summary:
Upload document for conversion. Although you will receive a response to an upload request quickly, the actual conversion process happens asynchronously. As such, receiving a successful response to an upload request does not imply the document has finished converting or that it is immediately available for viewing.
Parameters:
viewerURL: Provide the path as
documentUrl: URL of the document that you want to open
Sample:
var oViewer = new eViewerHTML5();
var viewerUrl = ‘http://mstsp2010:142’;
var documentUrl = ‘http://mstsp2010:144/SampleMVCApp/TestDocument.pdf’;
var sessionId = oViewer.uploadDocument (viewerUrl, documentUrl);
Returns:
UID assigned to the document. For ex: UID: 00000010-0000-0010-8000-00AA006D2EA4
You should be sure to keep the document's UID since it is required for other document actions such as viewing and deleting.
Document Status getDocumentStatus (viewerURL, sessionId)
Summary:
To know the current status of the uploaded document so as to determine whether the document has been successfully converted or not.
Parameters:
viewerURL: Provide the path as
sessionId: Unique ID generated when uploaded document
Sample:
var oViewer = new eViewerHTML5();
var viewerUrl = ‘http://mstsp2010:142’;
var documentUrl = ‘
var docStatus = oViewer.getDocumentStatus (viewerUrl, sessionId);
Returns:
Status of the document. The possible values can be
- DOWNLOADING: Downloading is in process.
- DOWNLOADED: Downloaded successfully.
- CONVERTING: Document converted in PDF
- UPLOADED: Converted PDF document loaded successfully.
- DROPPED: Deleted document.
- ERROR_DURING_CONVERSION: Error occurred during conversion
- UNAVAILABLE: Unable to find document
View Document viewDocument (viewerURL, sessionId, userId, username, redirect)
Summary:
View/open a document.
Parameters:
viewerURL: Provide the path as
sessionId: Unique ID generated when uploaded document
userId: User ID of the user
userName: User Name of the user (optional)
redirect: should always be ‘false’.
Sample:
var oViewer = new eViewerHTML5();
var viewerUrl = ‘http://mstsp2010:142’;
var documentUrl = ‘
var userId = ‘1’;
var viewerLoadUrl = oViewer.viewDocument (viewerUrl, sessionId, userId, ‘false’);
Returns:
URL to the viewer which can be set as the source of iFrame of opened in a new window which will load the viewer with the document.
Get Native Document getNativeDocument (viewerURL, sessionId, userId)
Summary:
Use to get the original document that you have uploaded like JPEG, PDF.
Parameters:
viewerURL: Provide the path as
sessionId: Unique ID generated when uploaded document
userId: User ID of the user
Sample:
var oViewer = new eViewerHTML5();
var viewerUrl = ‘http://mstsp2010:142’;
var documentUrl = ‘
var userId = ‘1’;
var nativeDocument = oViewer.getNativeDocument (viewerUrl, sessionId, userId);
Returns:
Downloaded byte array of the original document
Page Count getPageCount (viewerURL, sessionId, userId)
Summary:
Count the number of pages in a document.
Parameters:
viewerURL: Provide the path as
sessionId: Unique ID generated when uploaded document
Sample:
var oViewer = new eViewerHTML5();
var viewerUrl = ‘http://mstsp2010:142’;
var documentUrl = ‘
var userId = ‘1’;
var pageCount = oViewer.getPageCount (viewerUrl, sessionId, userId);
Returns:
Number of page in a document.
Thumbnail Document generateThumbnail (viewerURL, sessionId, userId, height, width, pageNo)
Summary:
Used to generate the thumbnail image of the page. Thumbnails maintain the proper aspect ratio of the page and are bounded by the dimensions specified in the parameters.
Parameters:
viewerURL:Provide the path as
sessionId:Unique ID generated when uploaded document
userId: User ID of the user
height: Height of the thumbnail image that has to be created.
width: Width of the thumbnail image that has to be created.
:pageNo: Page number of the document whose thumbnail image has to be created. A zero based page index.
Sample:
var oViewer = new eViewerHTML5();
var viewerUrl = ‘http://mstsp2010:142’;
var documentUrl = ‘
var userId = ‘1’;
var pageNo = 0;
var width = 80;
var height = 80;
var thumbJpeg = oViewer.generateThumbnail(viewerUrl, sessionId, userId, pageNo, width, height);
Returns:
Thumbnail image of the page in JPEG format.
Export Document exportDocument (viewerURL, sessionId, userId)
Summary:
Download the document in PDF format.
Parameters:
viewerURL:Provide the path as
sessionId:Unique ID generated when uploaded document.
userId: User ID of the user
height: Height of the thumbnail image that has to be created.
width: Width of the thumbnail image that has to be created.
:pageNo: Page number of the document whose thumbnail image has to be created. A zero based page index.
Sample:
var oViewer = new eViewerHTML5();
var viewerUrl = ‘http://mstsp2010:142’;
var documentUrl = ‘
var userId = ‘1’;
var pdfDocument = oViewer.exportDocument (viewerUrl, sessionId, userId);
Returns:
Converted PDF file.
Reorder Pages reorderPages (viewerURL, sessionId, userId, pageOrder)
Summary:
Used to reorder pages of the document
Parameters:
viewerURL:Provide the path as
sessionId:Unique ID generated when uploaded document.
userId: User ID of the user
:pageOrder: Comma delimited list of pages. The page numbers are Zero Based.
For ex: Suppose you are viewing document and the order of the pages in that document is 0,1,2,3 but you want the order of pages as 1,2,3,0. So this 1,2,3,0 will be the page order.
Sample:
var oViewer = new eViewerHTML5();
var viewerUrl = ‘http://mstsp2010:142’;
var documentUrl = ‘
var pageOrder = “4,3,2,1”;
var userId = ‘1’;
var reorderedPdfDocument = oViewer.reorderPages (viewerUrl, sessionId, userId, pageOrder);
Returns:
PDF document with reordered pages.
Extract Text from Document extractPageText (viewerURL, userId, sessionId, pageNo)
Summary:
Used to get the full text from a document. The extracted text is encoded using UTF-8. The text for each page is separated by the form feed character (U+000C). This method is available only if your account has text extraction enabled.
Parameters:
viewerURL:Provide the path as
sessionId:Unique ID generated when uploaded document.
userId: User ID of the user
:pageNo: Page Number from which the text to be extract. A Zero based page index.
Sample:
var oViewer = new eViewerHTML5();
var viewerUrl = ‘http://mstsp2010:142’;
var documentUrl = ‘
var pageNo = 0;
var userId = ‘1’;
var pageText = oViewer.extractPageText (viewerUrl, userId, sessionId, pageNo);
Returns:
The extracted text from a document.
Remove Document removeDocument (viewerURL, sessionId)
Summary:
This method permanently deletes content and all the links associated with the document.
Parameters:
viewerURL:Provide the path as
sessionId:Unique ID generated when uploaded document.
userId: User ID of the user
:pageNo: Page Number from which the text to be extract. A Zero based page index.
Sample:
var oViewer = new eViewerHTML5();
var viewerUrl = ‘http://mstsp2010:142’;
var documentUrl = ‘
var documentUnLoaded = oViewer.removeDocument (viewerUrl, sessionId);
Returns:
True, if the document is successfully removed.
Platform
Workstation Requirements
Hardware Requirements:
- Processor: 1.6 GHz or faster
- Memory: Min 2 GB RAM
- Available Disk Space: Min 512MB
Software Requirements:
- Browser that supports JavaScript
Server Requirements
Hardware Requirements:
- Processor: 1.6 GHz or faster
- Memory: Min 2 GB RAM
- Available Disk Space: Min 1 GB
Application Server
- Apache Tomcat 5.5.9 or higher
- JBoss 4.0 or higher
- IBM WebSphere 6.1 or higher
- Oracle WebLogic 9.0 or higher
- Oracle GlassFish
Documentation Learn to use our products and services more efficiently with free user guide. These technical manuals are intended to assist you with the information needed to operate our product.
Download a PDF copy of the User's Guide by clicking link below.
Need to talk to us? Click here for contact information.
Support Optical Character Recognition (OCR)
Searches and extract text from images with the tool used for character recognition - OCR. Sometimes it may happen that you want to extract text compressed in the image. With the help of this tool, the compressed text can be extracted from the image and can be used in a different file.

Advance PDF Redaction
Easily hides documents confidential information using predefined document redaction and image redaction macro options such as credit card, DOB, Name, passport number, age, gender, race, etc.Provides more than 20 predefined macros for redacting PDF files.